The Tesseract OCR engine analysis
Tesseract OCR engine harbours the ability to perform handwriting recognition. Although the initial use of the engine was not for handwriting, it can be trained to recognise handwriting with good accuracy.
Troubles before image pre-processing
Initially at the beginning of the week I spent far too long trying to do some handwriting recognition with greyscale images, using ImageMagick, and found that it was a laborious process which did not return much success. There were letters which were being mis-calculated, or just not even been recognised after a few rounds of training. Although this was disheartening and it felt like I had lost a couple of days, I had a light bulb moment: “Perhaps the greyscale images were too dark”.
An example of using the greyscale image, where it would identify some characters (after tagging) but it would fail to identify development:
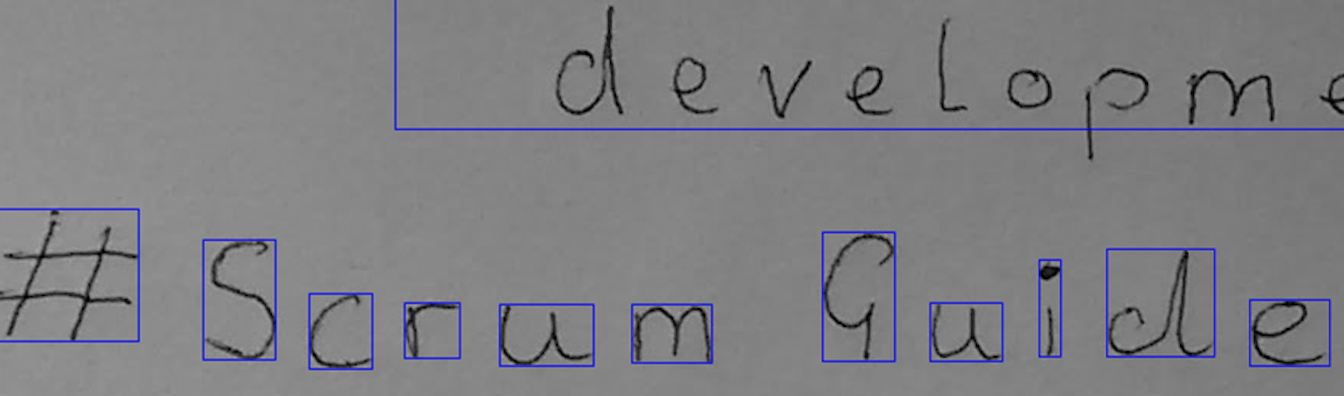
Playing with ImageMagick
My first aim was to convert the images to monochrome, instead of greyscale, and this resulted in a better recognition rate. After playing around with ImageMagick for a while and still not being 100% satisfied with my solution thus far, the task was left for a little while until I got some more information on it. During my meeting with my supervisor, it was suggested that I should look into using OpenCV instead of ImageMagick for the pre-processing of the notes; previous work had shown that OpenCV worked with the prototype web application, so why use another tool when OpenCV could help me already?
An example using the jTesseractBoxEditor tool with the monochrome image from ImageMagick, a problem I had was there was too much noise on the page.

OpenCV Binarisation investigation
Some tasks were raised to look into OpenCV and to begin an “experiment” into the OTSU method and various adaptive threshold functions, and how this would help with binarising the image. The real key for binarising the image was to reduce ambiguity with light sources and shadows on the photo of the notes (arms tend to get in the way and cast shadows). As stated above greyscale was proving problematic with detecting the characters, and even after a few rounds of training, errors such as a “-“ was being computed as an “m”.
Before deciding on an appropriate binarisation technique there had to be an investigation as whether Tesseract performed any such algorithms. In doing so I quickly discovered a paper from research developers working at Hewlett Packard Labs (where Tesseract first originated) stating that Tesseract uses the OTSU thresholding method - which instantly showed that potentially OTSU thresholding on top of OTSU thresholding would not return the best results.
Additionally when I looked at the source code it clearly uses the OTSU algorithm, implemented in C++. Another interesting thing I found was that Tesseract uses neural networks, in the source code there are files relating to neural networks, which makes sense with it being a black box learner (we’re not sure how it gets the answer we just get a value returned from it).
After some investigation into different pre-processing steps a collection of images were collated as such. This shows adaptive mean and adaptive gaussian return good results without the noise of the black at the top. Importantly, the OTSU method shows how Tesseract may be interpreting the images, hence the struggle with greyscale:

Starting out the experiments
So, following on from this it was clear I needed to identify a sensible thresholding algorithm for the images. It was suggested that I conduct a series of “experiments” on lined paper, plain paper and coloured line paper (I created my own due to the algorithm not identifying the coloured lines, and merely rejected them). This was conducted to analyse and present an answer for how my notes will be constructed as whether Tesseract favoured a certain pre-processing stage on specific paper compared to others.
With the coloured lined paper the initial idea was to use solid lined paper to which we can filter the lines so all the text remained uniform and straight, but appearing as though it was on plain paper removing the chance of additional noise. This caused me a few problems, mainly with what should I do when I actually filter the lines - should I colour them in or forget about them? When I initially filled them white it made the lines black on the adaptive threshold partly due to the change in contrast compared to the background.
I hummed and ahh’d over this for a while, but decided to just extract the text and anything which was within a black-grey threshold, therefore excluding the blue lines. This worked well as it extracted all of the text out of the image, and with the aid of eroding then I was able to clear the image up as best as possible - there was a loss of some pixels and some letters were undistinguishable, but for the most part it worked successfully.
With all this ready I was able to test this against the Tesseract engine to find out which of the documents would yield the best accuracy. To ensure consistency from the results the notes had the same text, the same number of characters, and where possible, a close structure (although this should not affect Tesseract).
The blue note, which I used to create - constant spacing and easily extractable blue lines.

The standard lined paper with the same content.

Plain paper version with the same content.

Testing the Tesseract OCR Engine
For each of the different test images which I created, I conducted the experiment with:
- The original image.
- The greyscale version of the image.
- An adaptive threshold version of the image.
My framework for remainder of the experiment was along these lines:
- Convert the image to greyscale
- Convert the image using an adaptive threshold.
- Run Tesseract on the normal Image.
- Run Tesseract on the greyscale Image.
- Run Tesseract on the adaptive threshold image.
- Calculate the number of characters (excluding spaces) it recognised
- Calculate the number of correctly identified characters (allowing captialisation instead of lower case)
- Calculate the accuracy percentage of correct characters / total characters
An important point to make is that the tests were performed against Tesseract’s default English language setting and not against any prior trained handwriting set.
Tesseract was ran as such:
tesseract input\_image\_type.tiff tesseract\_test\_results/exp0\_image\_type -l eng
Results from the experiments
Below is a table showing the number of characters identified in the text file, minus the spacing.
| Greyscale | Original | Threshold | |
|---|---|---|---|
| Blue-Lined | 85 | 119 | 157 |
| Lined | 19 | 261 | 1186 |
| Plain | 18 | 15 | 169 |
Below is a table showing the characters which were indeed correct in the text file - calculated by analysing the output file and roughly working out which characters were supposed to be associated with which part of the text. In the file each line is supposed to represent the line which Tesseract reads in the data - thus leading to a rough estimation, but nevertheless an important statistic.
| Greyscale | Original | Threshold | |
|---|---|---|---|
| Blue-Lined | 18 | 36 | 75 |
| Lined | 0 | 67 | 36 |
| Plain | 0 | 0 | 63 |
So, the results do not look that promising, but remember this has not been trained on my handwriting and had to deal with 267 characters on the page.
Below shows the accuracy of the correct results vs the number of characters on the page.
| Greyscale | Original | Threshold | |
|---|---|---|---|
| Blue-Lined | 6.75% | 13.5% | 28.0% |
| Lined | 0% | 25% | 13.5% |
| Plain | 0% | 0% | 23% |
An example quote from the adaptive lined file - the dots I believe are the lines on the paper being misinterpreted. However, it does try to identify lecturer: Neil, with IL being capitals.
l..e.c.é.u..rr.e.1:.’:Ne I-L..fr.01.
Finally, an example from the blue lined paper after the adaptive threshold. It is trying to identify the phrase, “- good for XP” but gets a lot of the characters correct.
- food For > < p
Thoughts and potential explanations
So what do the results show, well the best character recognition came with the adaptive threshold blue-lined paper, followed by lined paper’s original image and closely followed by plain adaptive threshold image. What’s important is that I see how I was not getting very good results with just the greyscale and ended up being very confused and a bit downhearted. This experiment, albeit with only one test example, shows that some form of adaptive threshold will help. Further forums suggest an adaptive approach is a good way to optimise Tesseract, and I will be looking at doing this to train my handwriting data. Additionally, I will attempt to train my handwriting on the lined paper I have made to see if the training process goes a lot smoother.