Sprint 7 Review
Today marks the end of sprint 7. I have been doing a lot more reflection this sprint, partly because I have to write about it, but also certain things came up this sprint which made me do some self reflection.
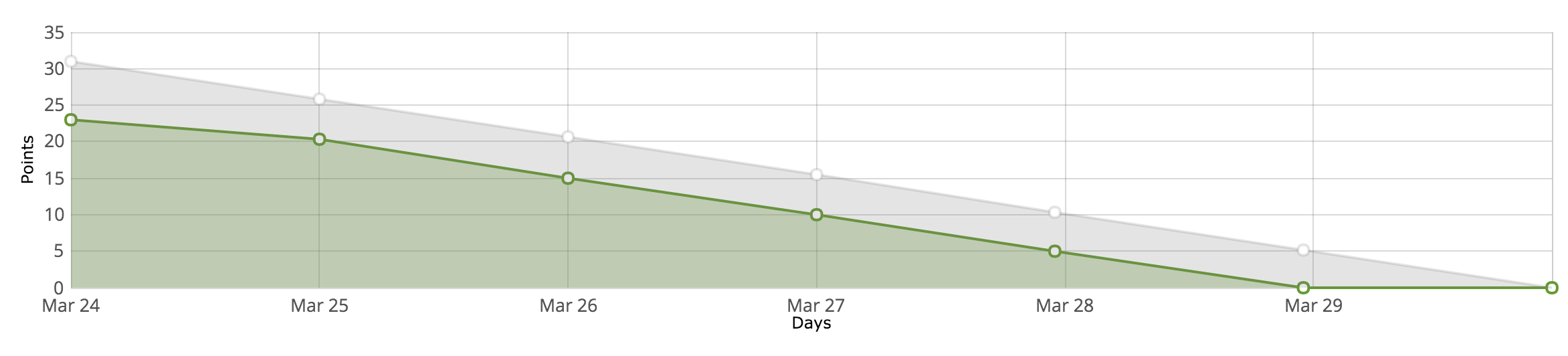
The burndown chart for this sprint show that I have completed another sprint, producing a release again this sprint. However, the linear line can be a bit misleading.
What I actually did
The primary goal of the sprint was to get the calendar integrated successfully to the application. I envisaged the application to “suggest” the date of the lecture when the user began to fill in their meta-data. This led me to question how I was going to do this. After a discussion with Hannah I decided to look into Exif data.
Exif Data parsing
Exif data provides a series of meta-data about an image, and one of the key fields it finds is start time. So I went away and completed the story: “As a developer I want to be able to get the date taken from EXIF data, to show information about a note”. This was actually fairly simple to implement as Python has a PIL (image library) which has a function to get the exif data. Once I found the standard for what the associated keys related to then parsing the start date to the user was a simple task. This now gets displayed to the user when they fill in the data (Note: This only works with .jpg images not .png etc - which I have factored into the code)
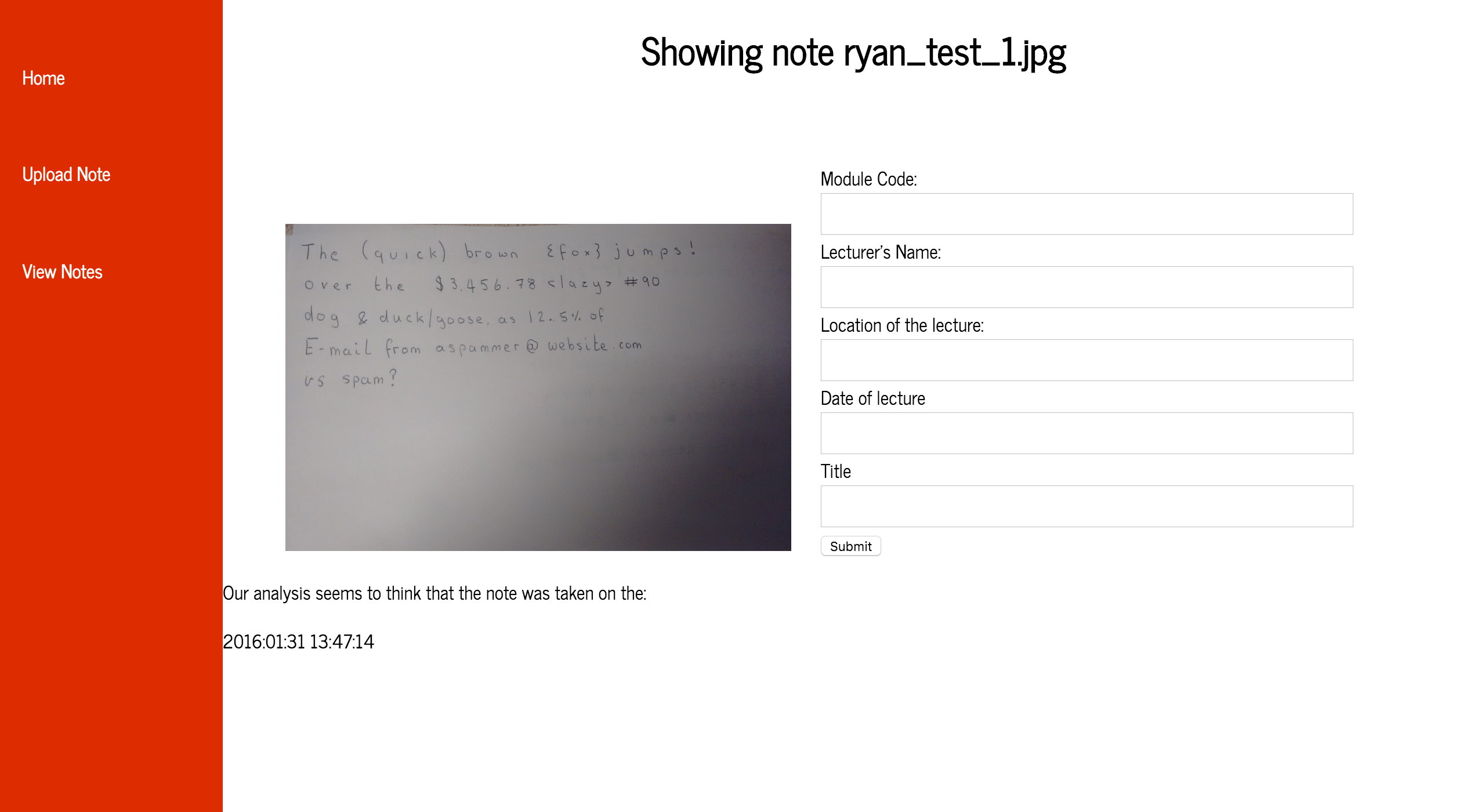
Calendar Integration
Afterwards I moved onto the story, “As a user I want to be able to save the URL in the calendars event”. This is where persistent problems began to unfold. Now, as I am doing TDD I follow the cycle of, writing tests, implement code and then refactor accordingly.
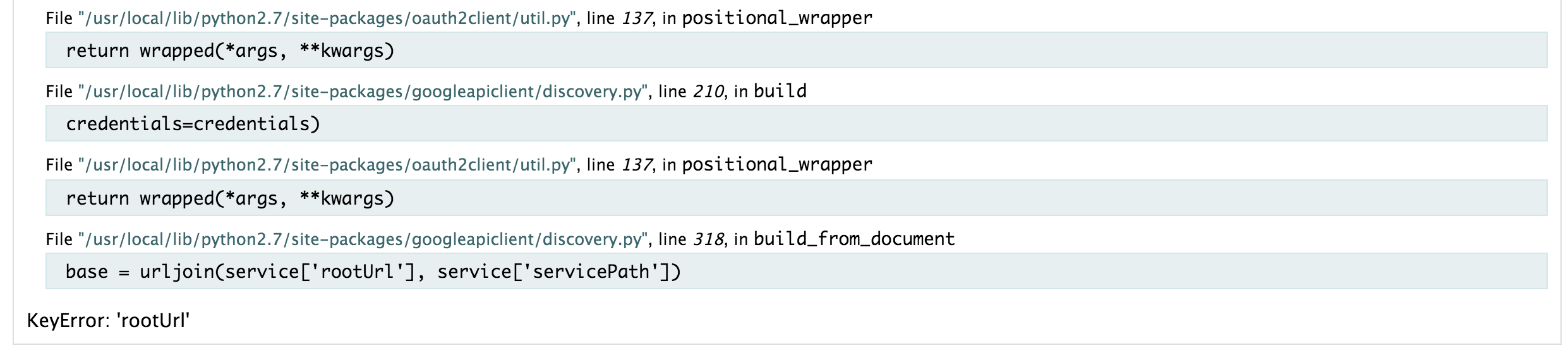
With the calendar there was no difference. However, I came across an unusual error with the google-api-client one morning: “Key error: rootUrl’. Huh? I had not changed anything why was it breaking. Naturally I did all the checks with my code, checkout to a branch which I showed my supervisor it was working only the day before and it was still getting this error. It was getting a little frustrating now, as I had no idea how to fix it. So I raised an issue on their github repo. The developers at Google were quick to reply and were actively looking to fix it, but they could not replicate the issue. This again was a hinderance and I started to think: “What if it doesn’t get fixed, a lot of my dissertation is under-complete”. What was more weird about the issue was that: discovery.build("plus","v1" ..) worked fine and returned the correct data but discovery.build("calendar", "v3" ..) would error. I gave up with the story that day, I thought it was an error server-side. I came back after restarting my laptop and the error was gone. I am not entirely sure that the actual issue is - maybe some caching of the calendar. Either way, it doesn’t explain why one worked and the other didn’t. I felt I lost a lot of time on development, and in all honesty probably was a snowball effect for the rest of the sprint.
After this inconvenience was passed I managed to get onto some development with the calendar. So for my testing strategy it consists of model tests, route tests and acceptance tests. Since the calendar integration was going onto a page with a form I wanted to keep the acceptance tests (using selenium) so that I could interact with the form. So I changed my test to a LiveServerTestCase from Flask-testing. I am mocking the Google Calendar response, a) to ensure the tests are consistent every time I run them. b) I don’t have a dev url to hit. Now trying to work out how to mock with selenium was difficult to say the least. Eventually I found mock.patch functions in Python’s mock library, which seemed to work with the LiveServerTestCase. Eventually I found the start stop patch, which would seem to work for these tests.
Eventually I managed to be able to implement something. I managed to get it to be able to use the Exif data from the image to find the events in a user’s calendar for that day which may be of interest to user in tagging module code and date. Then once the user had saved the note I would try and find the event from the date they inputted and where it contains the module code in the event name. When updating the event the url of the note is appended to the description field in the event. The algorithm is like this:
Create a calendar service object
Prepare url from saved note
Build the HTTP request
Find an event for that day from the start time as given
Parse the events
Check to see if the summary contains module code AND the start date time matches
If it does then update
check the response to see if description includes url
Save URL to the notes attribute in the database
This task took me far too long, partly due to the testing infrastructure not really helping me. The implementation was fairly quick, but the testing was the main cause of slowing down. Eventually the calendar was integrated with the add note. It suggests events and then when you save it will add to the calendar and give the user a url to view the event if it saved.
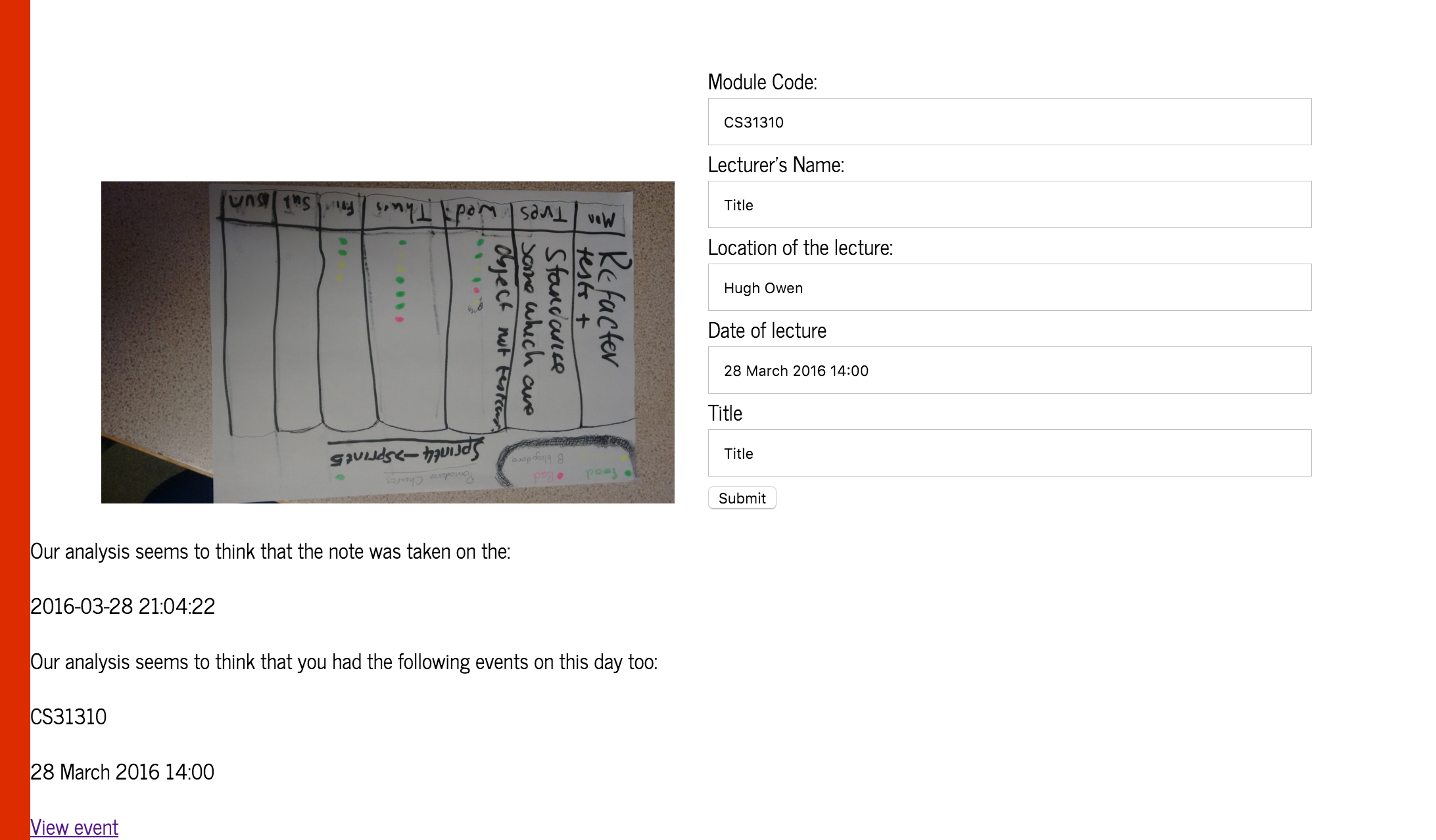
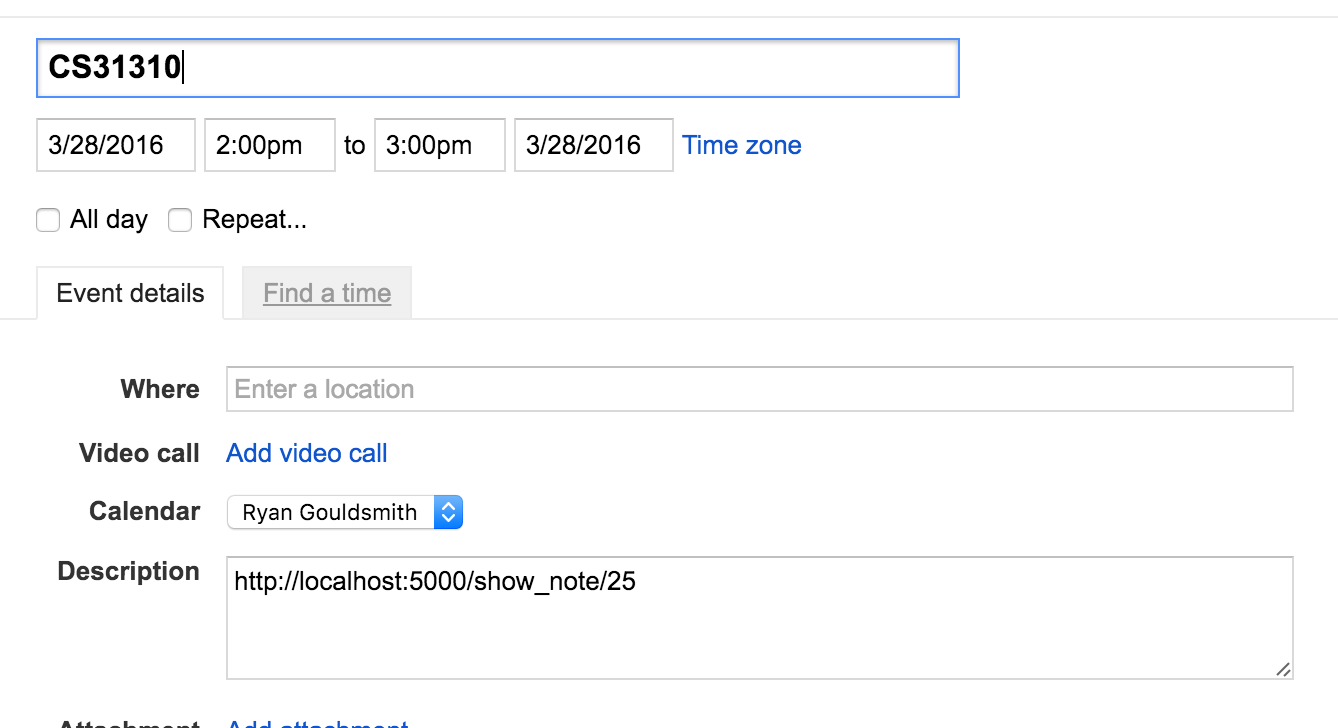

Searching for a note
The story for this was: “As a user I want to be able to search for a given module, so that I can find all notes for that module”. Whilst I thought the Calendar service broke. I implemented the search for a note. This was simple to implement, initially. I created a new blueprint route and found all notes based on the module code. Additionally here, I extended the original search view template for the search results - so that I only have to render the search form once.
Attaching a note to a user
The story for this was: “As a developer I want to be able to associate a note with a user”. When I initially started this I was not going to have the concept of user’s because of the complexity of the Tesseract handwriting training. Since I incorporated the Google+ API I now store users.
Therefore uploaded notes would have to be attached to a user and anywhere which integrates with the notes (search and view all) would have to be locked down to that user. I modified all the tests to add a user_id field to the class. User management has been implemented now and user’s can only view their own information. Again I created an abstraction layer for the session, this partly helps with the readability but mainly for the testing as testing with sessions is difficult.
Other bits of household stuff
I had to refactor all the tests because when I was mocking some of the tests were breaking. Now every test which would interact with the Calendar or something like a session would be mocked accordingly. This has meant that mocking has become a key feature in my test case.
Things which went well
- Integrated the Calendar to save a note
- Added search and user restricted content
- I kept by TDD and the process. I could not have mocked the Calendar / tried to do acceptance tests, but I continued.
- Managed to complete the sprint.
- Started to write the background chapter for my report.
Things which didn’t go so well
- Frustration with mocking and testing.
- Managing my own expectations of this project.
Things which I intend to do better next sprint
- Realistically realise what I can and can not achieve.
- Stop trying to think of extra things to include.
What to do this sprint
I believe I am close to reaching MVP. I just need to integrate Tesseract and then do some UI/UX improvements and I would have reached minimum expectations. Therefore, I will be looking to do the parsing of the meta-data from the Tesseract OCR (even if the results are terrible!)
I want to improve the UI so I can get it to a point where I can give it to some user’s to test and get feedback about certain aspects.
Reflection on the process so far
This could go in its own blog post but I might as well include it here, since this sprint I thought about it most.
Methodology
For a single person project some people argue that you end up “shoe-horning” a methodology to fit the criteria, but I disagree. I am adopting a Scrum approach with XP values, and I am finding it more beneficial than hindering. Sprints are a good way for me to split work down and analyse what I need to do, coupled with the reviews have been really helpful. TDD has been amazing, I have over 100 tests but they are useful tests which cover the code base well in all forms (ui, model, routing etc). Finally, the burndown chart has to be best. It has been imperative in the process for analysing how well I’ve been progressing. I aim to complete around 5 story points a day, and the graphs are a great way to see if I am doing this.
Infrastructure
This is my first web application in Python, and Python itself I am loving. I chose Flask for the minimalist framework, giving me for freedom but perhaps this was not the best option - given I am so focussed on testing, the testing sections leaves a lot to be desired. There is some good documentation on there, but when you want to do something slightly different it’s hard to find the information. The selenium tests for example were so hard to find out how to do them - then trying to modify sessions etc was a nightmare. Then there’s testing libraries for Flask and it all gets a bit confusing.
This leads me to say there’s a lack of documentation for a lot of things, not just Flask, with regards to testing - which is annoying.
Managing expectations
This is probably something I have struggled with the most. Partly due to the project having so much scope, it’s hard sometimes to think what you’re doing is not enough. No process could really help you with this. All that I can say is that I am putting a lot of effort into this to try and get it to MVP - so hopefully we’ll end up with a good system.
Overall Dissertation
The topic I am doing is interesting - handwriting notes to digital versions. I am glad I chose it, some parts have been tough but that’s fine, everyone likes a challenge. The main thing is I have learned a lot - technical and non-technical. I have treated it like a job (and probably a bit more) and I’d like it to be a good bit of work to end my time at University.
There’s still a few weeks to go, but these are just some thoughts I have thought the last couple of sprints - it’s good to reflect from time to time.