Sprint 3 Review
Today marks the end of sprint 3 and although I do not have a meeting today, I will be continuing the story points I did not achieve last sprint in this sprint.
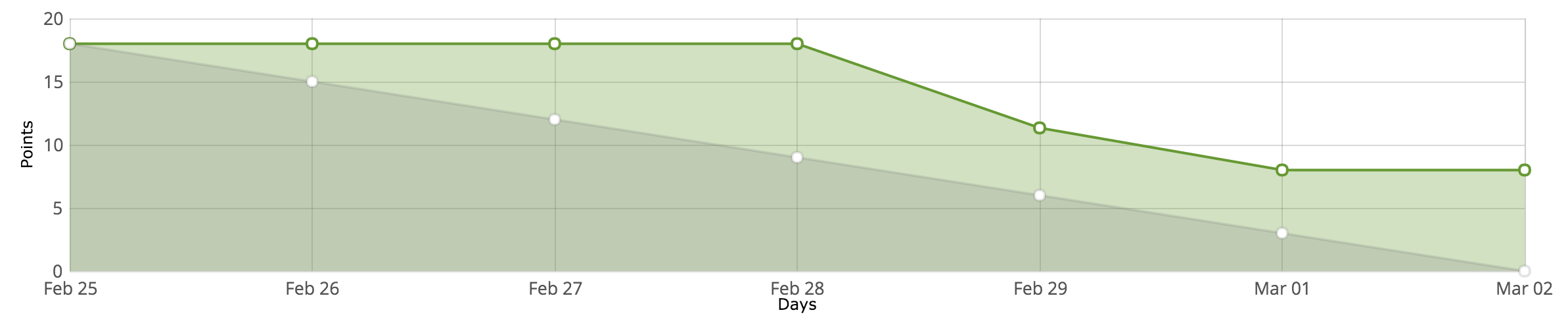
Overall, I probably estimated for two sprints, which is OK. I will roll the remaining stories and tasks to the new sprint. The first few days were a mixture of: collecting results, poster, passing driving test, weekend with no internet and more posters. Once I managed to get those out the way, I made some headway with the work.
###What I actually did I completed the story card: “As a user I want to be able to save a note, so I can find it again”. I found from the Flask documentation they recommend SQLAlchemy for the ORM and database interaction layer. A good thing about SQLAlchemy, and like all abstraction layers, if I chose to change my RDMS then it is as simple as changing a config file. The CRC card below helped with the design and made me think what I needed the note to store for this story point (note, no meta-data is stored in this one)

One thing I found which will be incredibly useful is Flask-Migrate and with the help from this tutorial things started to make sense with them. I am for migration files - working with both Ruby on Rails and Propel ORM in PHP I can see their benefits, and I think they keep the SQL schemas all together and it’s easier to track changes. Sadly, Flask doesn’t come with this stuff out the box (which I am finding to be a bit frustrating). There only seems so many ways to create a database migration manager, as shown in the tutorial, so appropriate referencing and adapting for my own project was completed. This does autogenerate the migrations directory along with a load of boilerplate code (again this has been noted in the comments that running this script generates the directories and are not my own).
Finding this migration feature was useful as I was able to edit the Alembic files (what flask-migrate is practically a wrapper for). Specifically, editing the upgrade and downgrade is important here. I think because it looks to try and find all the models, and I am developing using TDD, I had to create the schema before my model, so editing the upgrade/downgrade was needed. This lead to my first database table called notes, storing the image path.
After much consideration, I chose a RDMS database over a NoSQL, mainly because I found that majority of the data I need for MVP is structured so let’s not worry about it. I then had the decision of SQLite vs MySQL vs PostgreSQL. This article had a nice little comparison. I previously used SQLite with a ROR application, but would it be suitable for this? Well, development/testing maybe but not for a bigger application. With that out the window, I came down to MySQL vs PostgreSQL - now I chose PostgreSQL because it was slightly more advanced than MySQL and I’d like to have an application which uses it properly. Again, if I find that PostgreSQL maybe was the wrong decision, I can change the database - run some migrations and be in the same place (yay for abstraction).
Anyway, so I had a database, time now for some tests. They were fine to write, however, I was noticing I was using the production (development in my case) database, so I quickly changed that. At the moment I am only using the database for simple read and writes by a singular person, so a temporary SQLite database was chosen. Again, I am not sure if this is wise - but everything interacts fine, I may switch it for a test PostgreSQL one, but I will see.
With all the infrastructurey stuff set up, I was able to crack on and get the note saving to the database. I tested the model before integrating it into the upload blueprint (route) and saving the note on upload.
With this change I managed to be able to do my first big refactor. Replacing all string with variables etc as well as creating file_exists function as functionality was being duplicated. The code base seems in a sensible place for now. I have blueprints instead of all the routes in one file. I have service objects for routine model stuff but have I have kept the model specifically for the database interactions and persistence.
Finally, I have investigated how to do some selenium testings with a headless browser so I can do the E2E (end-to-end) testing. This took a little longer than I wanted to. A lot of the issues were that selenium for Python didn’t like working with localhost etc, and to do so needed a selenium server. I didn’t want to run an additional server for it - so I thought there must be an easier way. Eventually, I came across the Flask-Testing framework. This has a LiveServerTestCase which will spin up a server of the application and test against this. I can interact Python selenium with this. These tests were put in place for me starting the task of adding the meta-data form to the view files.
Things which went well
- Completed a user story of saving a user’s note to the database so it can be retrieved again.
- Got a lot of the infrastructure decisions made with the database choice etc.
- Finally got some E2E tests in progress.
- Pre-mid project demo went well.
Things which didn’t go so well
- I lost some time this week with various things, so I feel progress halted for a while.
- I think Flask is a great micro-framework, but that’s all it is a micro-framework. A lot of the additional work you really have to search for to make it a good robust project. Although I do find it fun to develop in, I wish things were a bit easier to find.
Things which I intend to better next sprint
- I’ll be doing planning shortly, so with my supervisor away this sprint I want to get the estimation spot on this sprint.
- Put the application up online, rather than locally. This will be ready for the mid-project demo.
- Train some more handwriting.
- Write up the segmentation script into TDD.
What do to this sprint
Continue with the good backing I have now. I will be looking to add the meta-data form and integrate this into the database.
I will also be looking to the Google API’s and how easily it will be able to tie into the application.
More training of the handwriting to really reinforce that.

So this sprint (minus the story points I am currently working on) marked the “I am over 50% of the way through the MVP backlog” Judging by the points remaining and the current points per sprint, by the end of Easter MVP should be complete. How hopeful I am with that depends on obstacles along the way; it could either one of two ways with the infrastructure set up: quickly or painfully slowly. Hopefully it’s the former :)