Sprint 1 Review
Today marks the day of Sprint 2, leaving behind Sprint 1. The previous sprint was mainly used to train handwriting data and optimising images for the Tesseract OCR engine.
Below is my burndown chart from Sprint 1.
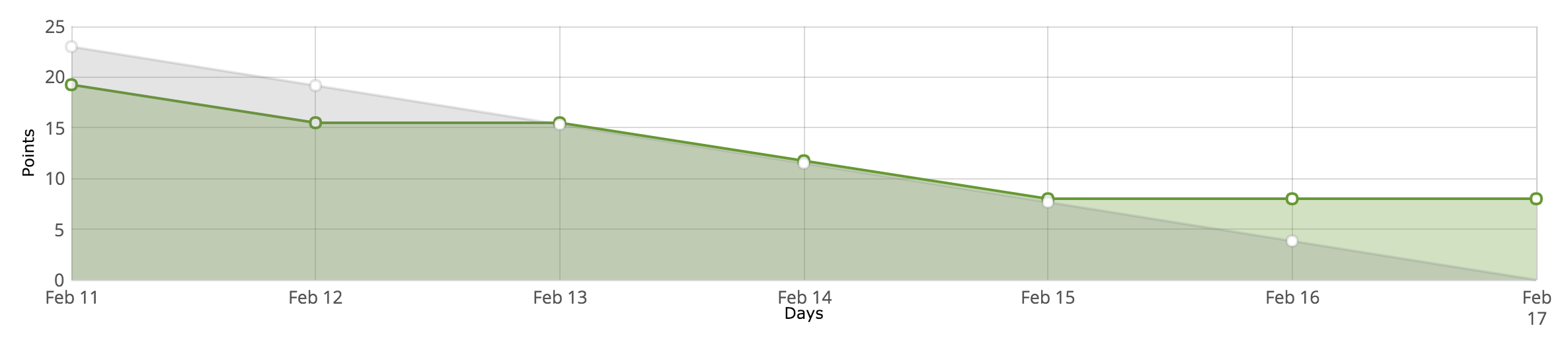
I completed all but 8 story points from Sprint 1, mainly due to finding an issue with Travis CI. Having spoken to my supervisor we have agreed that it’s OK as it’s not a priority, so we will continue this task over the next few sprints to see whether it will be worth it.
Things which went well:
- Got some adaptive threshold to work
- Training my handwriting to a reasonable success so far, needs more data.
- Generated lots of test data.
- Created my own notes.
- Rewrote the spike work removing blue lines into more formal code applying TDD and structured into classes and functions
- Learned more about Tesseract and Open CV optimisation techniques.
- Continued to do (bi)-daily stand-ups as there was nothing to really discuss.
Things which didn’t go so well:
- Travis deployment is still proving a bit complicated
- Training the data is a long process as I have to manually go through and tag an entire page of characters per training example. (my hand hurts after a lot of writing)
Things which I will do better in this sprint:
- Start to use CRC cards for the development
- Estimation of tasks probably
- Bringing 25 story points into the sprint
- Re-estimated the Travis CI story, but I am blocked on a task due to lack of knowledge.
- Do daily stand-ups now that I have started actual development.
Agreed work for this sprint:
- Upload an image to the web application and a user will be able to view their upload and make this ready for production
- Look into removing additional noise from images.
- Continue to reinforce my handwriting with some more training examples.